Introduction
ExGRPO: Learning to Reason from Experience is a paper submitted to arXiv on October 2, 2025, by Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, and Yu Cheng. It proposes a new method in the domain of reinforcement learning with verifiable rewards (RLVR), improving on the earlier GRPO framework by introducing experience replay of reasoning trajectories. The authors’ central message is that not all experiences are equally valuable, by selecting and reusing high-quality, low-entropy reasoning traces, one can substantially boost learning efficiency and stability in reasoning tasks.
Reinforcement Learning with Verifiable Rewards (RLVR) frames reasoning as asking a model to generate “chains of thought” whose final answers can be checked automatically. Yet, standard on-policy RLVR methods discard rollout experiences immediately after a gradient update, which is wasteful, particularly when correct reasoning trajectories are rare. This omission undermines both efficiency and training stability.
The authors begin by analyzing what makes a reasoning trajectory “valuable” for learning. They identify two signals:
- rollout correctness: how many of the sampled answers for a question were correct and
- trajectory entropy: how confidently the model acted.
They observe that trajectories of intermediate difficulty and low entropy tend to carry the most beneficial learning signal.
Based on these insights, they propose ExGRPO (Experiential Group Relative Policy Optimization). ExGRPO maintains a replay buffer of past successes, partitions them by question-level correctness, and preferentially samples those with low entropy. During training, it mixes on-policy rollouts with replayed trajectories in a balanced objective, applying importance-weight corrections to account for distribution shift.
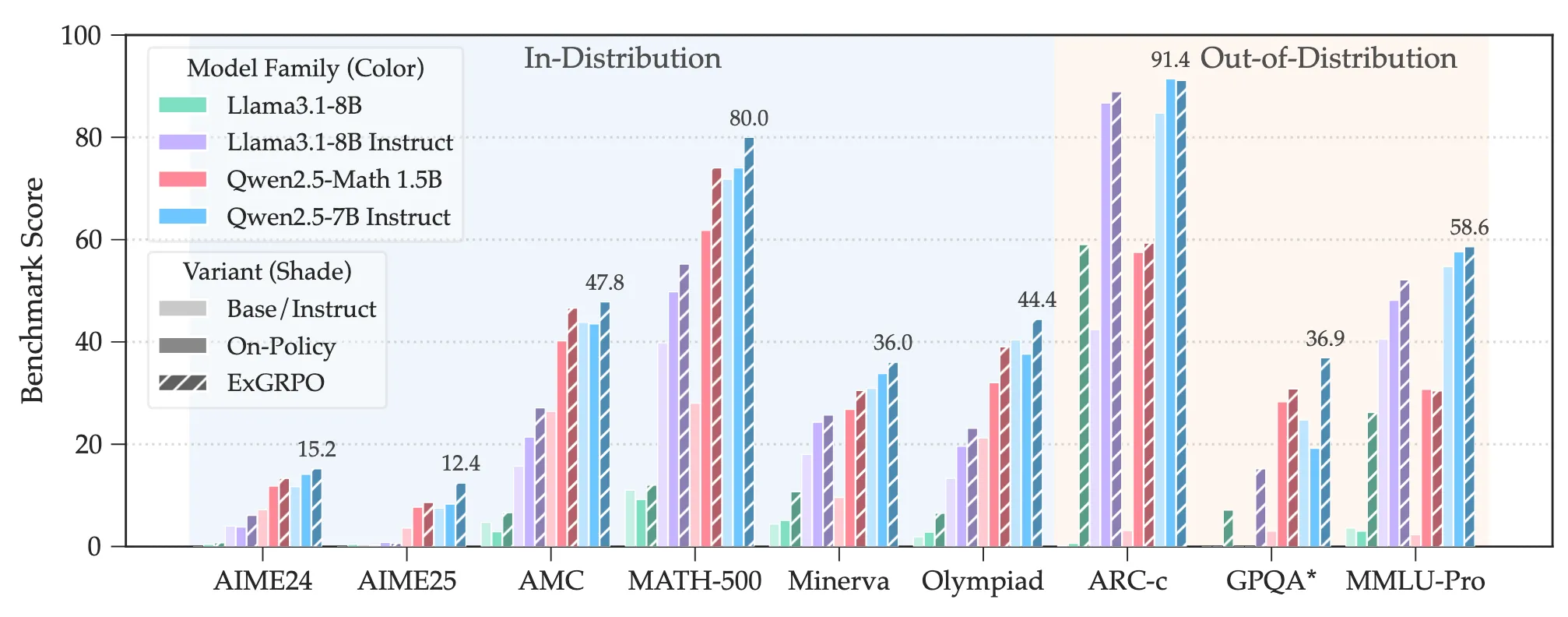
Empirically, across models from 1.5B to 8B parameters and benchmarks both in-distribution (math tasks) and out-of-distribution (reasoning generalization), ExGRPO yields consistent gains over pure on-policy RLVR. The authors report average improvements of +3.5 points on in-domain reasoning and +7.6 points out-of-domain. They also show that ExGRPO helps stabilize training on weaker models, where pure RLVR often collapses.
Experiments
We instantiate a controlled arithmetic reasoning environment (addition/subtraction with verifiable answers) to compare on-policy GRPO against an ExGRPO-style replay variant. Each example provides a 4-dimensional feature vector , a unique id, and the true integer answer, enabling binary, automatically verifiable rewards for every sampled rollout.
The dataset is generated in a bounded range (answers constrained to ), and exposed through a ReasoningDataset with explicit ans_to_act / act_to_ans mappings so the policy acts over a discrete action set of integer answers. You will find the implementation in a notebook available here.
Model and on-policy GRPO
The policy is a compact MLP (5×256 ReLU blocks) producing logits over all candidate answers; action probabilities are obtained via softmax. At each update we perform grouped rollouts, sampling actions per question, then compute group-relative advantages by standardizing rewards across the attempts:
def group_adv(rewards, eps=1e-8):
m = rewards.mean(1, keepdim=True)
s = rewards.std(1, keepdim=True).clamp_min(eps)
return (rewards - m) / sThis pairs with rollout_group (categorical sampling, entropy logging) and a binary verifiable reward in compute_rewards, faithfully mirroring RLVR’s “right/wrong” supervision. The RLVR framing and its motivation are aligned with the ExGRPO paper’s setup.
ExGRPO: replay buffer, prioritization, and off-policy correction
The ExGRPO implementation introduces a trajectory buffer that stores only verified-correct rollouts together with their old log-prob, entropy, uid, and collection step. It enforces diversity caps per uid and recency- and uncertainty-aware prioritization when sampling:
# priority ~ recent & confident
w = math.exp(-age / float(tau)) * t.reward / (1.0 + t.ent)This favors recent, low-entropy successes, returning a candidate set with distinct uids up to a target per size. The original paper explicitly argues that valuable experiences tend to be lower-entropy traces from non-trivial cases.
During training, ExGRPO blends on-policy and off-policy terms using a mixing schedule with warm-up, peak, and decay phases, starting as pure GRPO and progressively leveraging replay as the buffer matures:
def mix_schedule(ep, warm=5, peak=40, lam_max=0.5, lam_min=0.2, alpha=0.03, beta=0.01):
if ep <= warm: return 0.0
if ep <= peak: return min(lam_max, alpha * (ep - warm))
return max(lam_min, lam_max - beta * (ep - peak))We set warm=5, peak=25, mix_max=0.5, mix_min=0.2, so replay activates after epoch 5 and ramps to its maximum by epoch 25.
Off-policy updates apply per-trajectory importance ratios with epoch-dependent clipping and a small KL regularizer toward the current policy distribution:
lp_new = logp_all.gather(1, a.view(-1,1)).squeeze(1)
w = torch.exp(lp_new - lp_old).clamp(0., is_clip) # clipped IS
# light KL reg toward current distribution
with torch.no_grad():
p_curr = F.softmax(policy(f), dim=-1)
kl = (p_curr * (logp_all - torch.log(p_curr + 1e-8))).sum(dim=1).mean()
loss_off = -(w.detach() * lp_new).mean() + cfg["kl_beta"] * kl
loss = (1 - lam) * loss_on + lam * loss_offThis matches ExGRPO’s mixed-policy objective and importance-corrected replay spirit (distribution shift control), consistent with the paper’s stated methodology.
Training configuration
We use Adam (lr=3e-4, bs=128, K=16, epochs=50, seed=0). Replay specifics: per=256, recency_tau=300, buf_maxlen=3000, uid_cap=3, and a small kl_beta=1e-3. These directly implement the “reuse confident, recent successes while keeping diversity” heuristic.
Results
Across 50 epochs, ExGRPO consistently outperforms GRPO on validation accuracy. The notebook’s final summary reports:
GRPO = 0.3935, ExGRPO = 0.4505 (absolute +0.057, ≈+14% relative), with ExGRPO taking the lead shortly after replay turns on (post-warm-up). The learning-curve figure labeled “GRPO vs ExGRPO” shows faster rise and smoother plateau for ExGRPO, whereas GRPO exhibits more oscillation, consistent with reduced gradient noise when reusing curated successes.
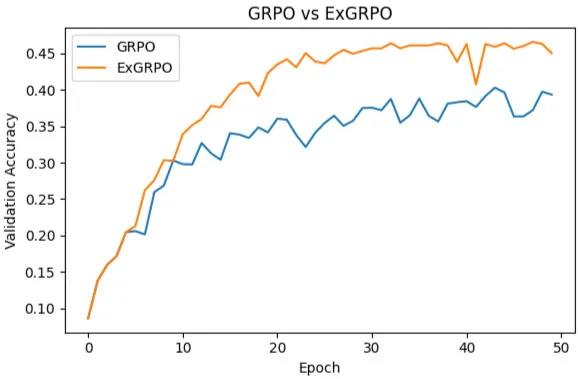
These empirical observations mirror the efficiency and stability benefits highlighted in the paper. While our toy arithmetic setting is intentionally minimal, the directionality aligns with the paper’s central claim that principled experience management boosts RLVR training.