Introduction
In “Geodesic Calculus on Latent Spaces” by Hartwig et al., they propose a practical Riemannian toolkit for deep generative models: learn a projection onto the data manifold that lives inside a model’s latent space, and then use it to compute geodesics, exponential maps, and related operators in a numerically robust way.
Latent spaces of autoencoders and VAEs are not flat Euclidean clouds; around the data they behave like curved manifolds. Linear interpolation cuts through “holes” (low-density regions), often producing blurry or invalid samples. The paper shows how to build a reliable geometric calculus inside latent space, so we can move along the manifold: shortest paths (geodesics), shooting via exponential maps, etc., without requiring perfectly accurate decoders or explicit charts. This extends a growing line of work on the Riemannian view of deep generative models (The Riemannian Geometry of Deep Generative Models, Shao et al.)
The core idea is to treat the true data manifold as an implicit submanifold of the ambient latent space and learn a projection onto it (via denoising); then perform discrete Riemannian calculus by repeatedly stepping in latent space and projecting back onto the manifold.
Mathematical essentials
-
Manifold in latent space. Let be the ambient latent space of an autoencoder, and the (unknown) subset carrying the data distribution . We do not parameterize explicitly; we only assume access to samples near it.
-
Projection . Learn a map with for and for noisy/off-manifold . A simple training objective is denoising:
which encourages fixed-point and idempotence properties typical of projections. This is the key robustness lever of the paper.
-
Discrete geodesic energy. For a path with endpoints ,
approximates squared length. The algorithm alternates gradient steps on in with projections . The projection enforces manifold feasibility; the gradient tries to shorten the curve, together yielding a discrete geodesic. (Regularizers can keep near the VAE prior.)
-
Exponential map / shooting. With , one can numerically realize the exponential map by short projected steps starting at in an initial direction , enabling “shooting” of geodesics from a point.
This “project–optimize–project” pattern does not require a perfect decoder metric or explicit tangent frames, only a good projection.
What the experiments show
Across synthetic and real datasets (with different autoencoders), the learned yields:
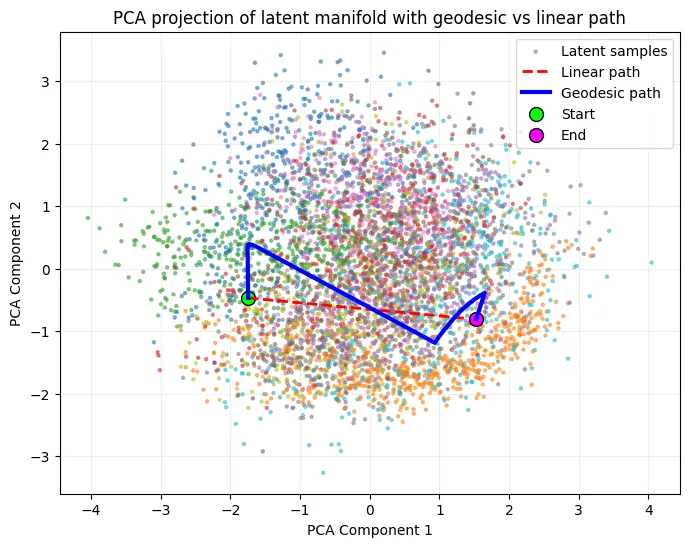
- Smooth, valid interpolations: projected geodesics stay in high-density latent regions; decoded frames are crisp and semantically consistent, unlike linear latent blends that traverse holes.
- Robust calculus: geodesic paths and exponential shooting remain stable even when the manifold is only approximately represented.
How it compares
- Versus linear latent interpolation: linear paths are cheap but ignore curvature/topology; they often decode to implausible images mid-way. The paper’s geodesics are longer (because they bend around holes) but faithful to the data manifold.
- Versus explicit Riemannian metrics: previous work builds metrics from decoder Jacobians; accurate but brittle and costly. Here, externalizes manifold knowledge and makes calculus projection-based, which is numerically simpler and decoupled from the decoder.
Where to use it
- Generation and editing: semantically consistent morphing (e.g., pose or identity changes) and “move along the manifold” operations.
- Representation learning: geometry-aware distances and retrieval along geodesics instead of Euclidean shortcuts.
- Robotics / motion planning: learned manifolds of feasible states with geodesic skills.
A minimalist recipe
- Train an encoder-decoder (VAE/AE) on your data.
- Collect latent codes and train a small MLP with the denoising loss above; optionally add fixed-point/idempotence penalties.
- Geodesic between : initialize linearly; iterate (i) gradient descent on discrete energy in , (ii) project internal nodes with ; clamp endpoints.
- Decode the path to visualize a geometry-aware interpolation.
Experiments
The experiments conducted in this notebook translate the theoretical framework of the paper into a concrete implementation on the MNIST dataset.
A VAE was first trained to learn a structured 16-dimensional latent representation of handwritten digits, where proximity between points reflects visual similarity. On top of this learned manifold, a projection network was trained as a denoising operator that maps any noisy or off-manifold latent code back toward the manifold of valid encodings, effectively approximating the Riemannian projection operator described in the paper.
Using , we computed discrete geodesic interpolations between latent representations of two digits (for example, “2 → 9”) by iteratively optimizing a path to minimize its energy while keeping each intermediate point projected onto the manifold. The resulting geodesic paths produced smoother, semantically coherent digit transitions than conventional linear interpolations.

Finally, PCA visualizations of the latent space revealed that the learned geodesic trajectories bend through dense data regions, faithfully following the manifold’s intrinsic geometry rather than cutting across low-density zones. These results empirically confirm the paper’s core idea: that a learned projection operator can endow deep latent spaces with a consistent geometric structure, enabling manifold-aware interpolation and analysis.